 }
}
Does Google Index JavaScript? Impact of JavaScript Rendering
Updated 01 February 2024
When evaluating a website from a technical SEO perspective, one of the most fundamental things you need to check is indexing.
At the most basic level, you need to understand;
- If the pages that should be indexed are actually indexed
- If the pages that should not be indexed are actually not indexed
Indexing is intertwined with crawling. Google crawls a page, indexes what it finds, extracts more links for crawling, crawls a page, indexes what it finds, extract more links for crawling... you get the idea.
Over the last few years, Google has also started rendering web pages, which is even more intertwined with the crawling and indexing process.
In this article I will try to clarify where rendering fits into the equation and how it can have an impact on indexing - so you can better understand and answer the two questions above.
Table of contents
You can jump to a specific area of the guide using the jumplinks below:
- What is browser rendering?
- The evolution of crawling
- How Googlebot handles rendering
- Why is using a Chromium based crawler important?
- How to compare response vs render
- Why you need to investigate this stuff
What is browser rendering?
The word 'rendering' exists in many other fields; so in order to disambiguate, what we really mean is 'browser rendering'. However, within the field of SEO, this is almost always simply referred to as 'rendering'.
Rendering is a process carried out by the browser, taking the code (HTML, CSS, JS, etc...) and translating this into the visual representation of the web page you see on the screen.
Search engines are able to do this en masse using a 'headless' browser, which is a browser that runs without the visual user interface. They are able to build (render) the page and then extract the HTML after the page has rendered.
Does Google index JavaScript?
Since 2017, Chromium has included 'Headless Chrome', which was a significant stepping-stone for Googlebot, in terms of Google's ability to render web pages at scale. Similarly, access to this technology allowed website crawling tools (like Sitebulb) to also crawl and render JavaScript like Google does.
Googler Martin Splitt published a short video explaining how rendering works, which is well worth a watch if you are unfamiliar with any of these concepts:
The evolution of crawling
Several years ago, crawling was a more straightforward task. Googlebot (and other search engine crawlers) would extract the response HTML and use this as their source of data.
Effectively, it was like downloading the data you see when you 'View Source':

Google would then 'parse' this HTML - which means to break it down into its component parts (text content, images, links, etc...) - and use this to update the index. Any links it found would get sent off to the crawl queue for scheduling.
However, over the years this method has become increasingly inadequate, as more and more sites become more heavily dependent upon JavaScript.
JavaScript is significant because when it fires, it can change the page content. So what you see as the 'page HTML' in View Source may be partially, or completely, different after JavaScript has fired.
When we consider the response HTML (i.e. View Source), this is before JavaScript has fired. When we look at a page in a browser, in order to render the page content, the browser is firing JavaScript and applying any changes.
This means that the data in the response HTML might be different from the 'rendered HTML' (what the browser is displaying). Since Google cares about what the user sees, they have become more interested in using the rendered HTML instead of the response HTML to make indexing decisions.
How to view rendered HTML
Just as 'View Source' gives us an easy way to see the response HTML, we can easily see the rendered HTML of a web page by using 'Inspect' (or 'Inspect Element' on some browsers).
On Chrome this looks like:
What this opens is the Developer Tools, and on the 'Elements' tab this shows the rendered 'DOM' (Document Object Model).
If you are unsure what a 'DOM' is or are unfamiliar with the phrase, then a bit of additional reading might help:
Whether or not you did the extra reading above, don't be put off by the phrase. Effectively, we can consider this to be the rendered HTML.
Differences between response and rendered HTML
Look at my two examples above - notice how the rendered HTML is almost identical to the response HTML. This is because the Sitebulb homepage is not heavily dependent upon JavaScript, so very little changes when the JavaScript fires.
Consider the side-by-side images below, which show the other end of the scale:
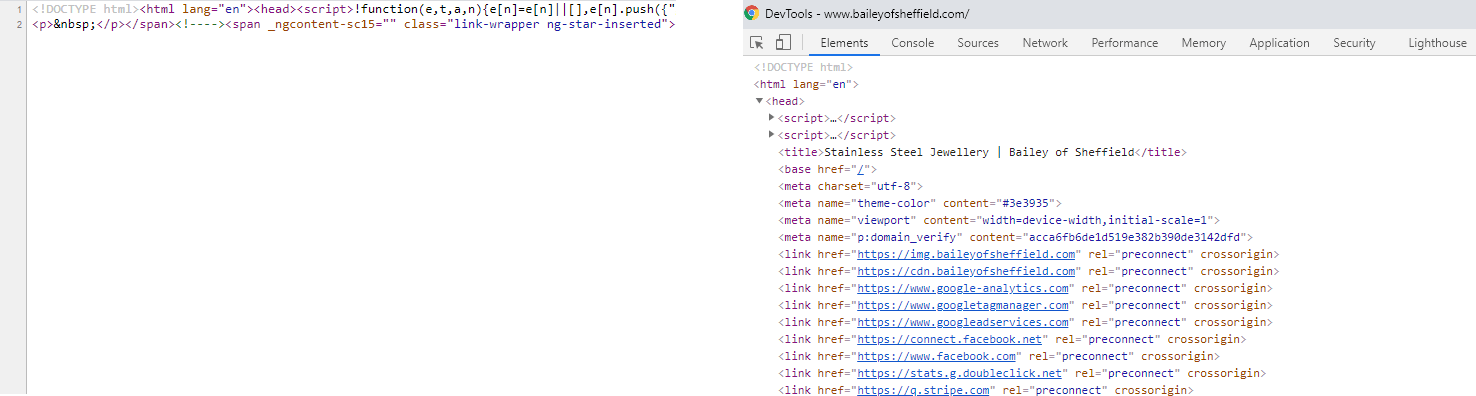
This is a web page that is almost completely dependent on JavaScript. View Source (on the left) basically contains nothing but some scripts. Inspect (on the right) shows 'normal looking' HTML, which is the data that has populated once the scripts have fired.
There is of course plenty of websites that are somewhere in between - they have lots of the core HTML present in the response, but JavaScript also changes some of the content during rendering. These are arguably the sites for which it is most important you understand how JavaScript affects Google's understanding of the page.
How Googlebot handles rendering
We can make better sense of what's happening by considering how rendering fits into Google's crawling and indexing process:
- Google's crawler picks a URL from the crawl queue
- It checks robots.txt to see if the URL is disallowed
- If allowed, it makes a HTTP status request
- If status 200, it extracts the response HTML
- IN PARALLEL:
(a) It checks robots data, and extracts href links it finds in the response HTML, and sends these into the crawl queue
(b) The URL gets queued for rendering, it gets rendered, and then the rendered HTML is sent back for further processing - The rendered HTML is now parsed and processed, any more links that were found are sent into the crawl queue, and the content is extracted for indexing
- The URL and page content is indexed
In graphical format, this looks like:
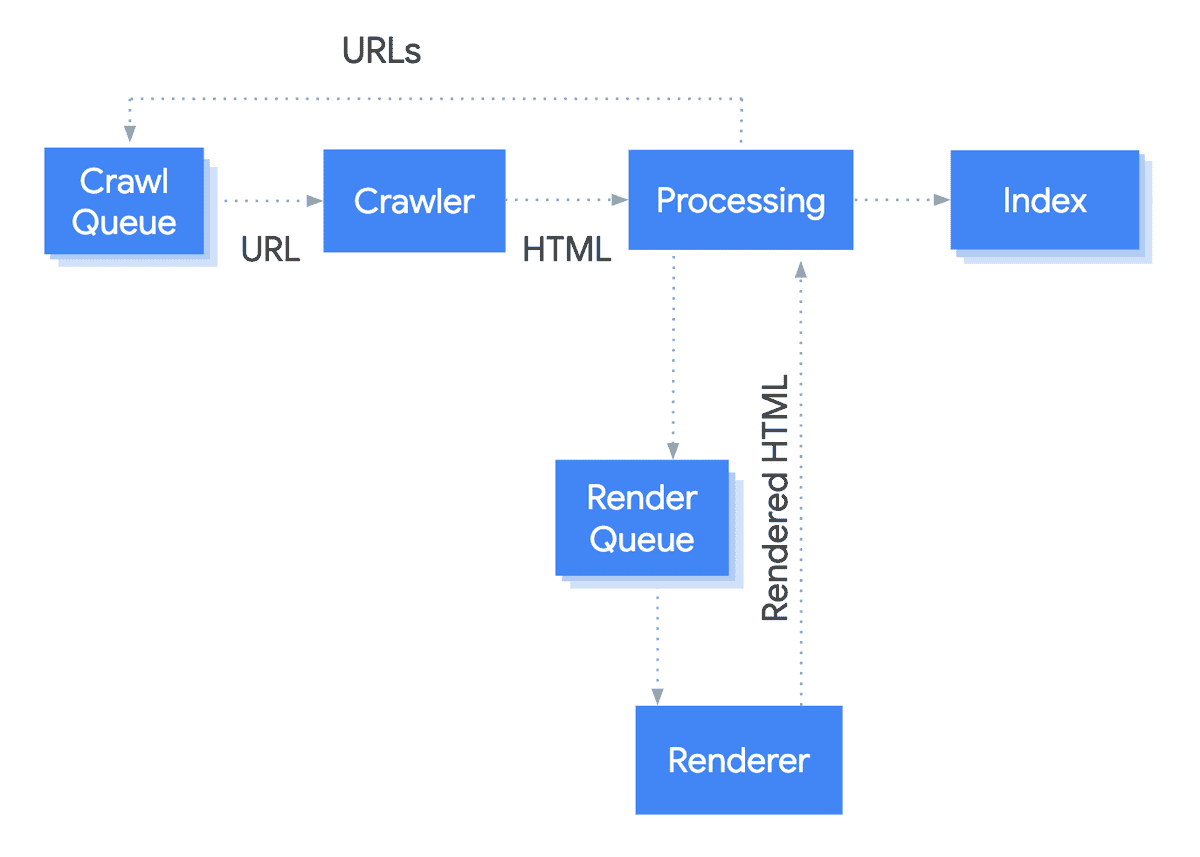
Stage 5 is the most complex to get your head around, because things are happening in parallel. It is also necessarily more complicated, because Google are making decisions on which pages to render based on the result of the meta robots check.
Specifically, from their documentation Understand the JavaScript SEO basics;
"Googlebot queues all pages for rendering, unless a robots meta tag or header tells Googlebot not to index the page."
Essentially what this means is: noindex = no render
And all of this is simply the process that Google use, who are typically at the technological forefront when it comes to crawling and indexing. Other search engines are likely less sophisticated in terms of what they can render and how it affects indexing.
Either way, the key takeaway is this:
In order to evaluate how Google are analysing pages on your website, you must crawl and render pages using a Chromium based crawler.
Why is using a Chromium based crawler important?
The crawling tools that SEOs use for site auditing and technical SEO are, by default, set up to consider the HTML response, NOT the rendered HTML.
Literally all of them are set up like this.
I mentioned earlier that the improvements Google made to Chromium allowed crawling tools to make use of Headless Chrome for rendering. But they won't do this UNLESS you change the default settings.
In Sitebulb you have to change to the 'Chrome Crawler' in the audit setup process, in Screaming Frog you have to select rendering from a setting menu, in SaaS crawlers like DeepCrawl and OnCrawl you have to pay extra to enable rendering.
Given the above, it is reasonable to ask why this is the case. The answer is threefold:
- It's the way it was always done, and inertia is a thing.
- Rendering is slower, and uses more computer resources, which makes it more computationally expensive (and explains why the SaaS tools need to charge extra for it).
- Lots of sites are not greatly affected by rendering (in terms of the HTML that SEOs care about)
Based on the final point above, on a lot of sites you can probably get away with only crawling the response HTML. For instance, I know from my experience of crawling the Sitebulb site many thousands of times that I am totally fine using the HTML Crawler.
But for brand new clients sites... 'you don't know what you don't know' means that you could be missing a huge chunk of important data if you only ever audit websites through the lens of the HTML response.
This is more important on some websites than others
When it comes to this sort of thing, you can essentially place all websites into one of 3 buckets:
- The rendered HTML is effectively the same as the response HTML
- The rendered HTML is significantly different to the response HTML
- The rendered HTML is somewhat different to the response HTML
The Sitebulb site is an example of #1, as we have already seen. It is no problem to crawl this site with the default crawling options.
Sites built using JavaScript frameworks (e.g. React) are examples of #2. These ones are pretty easy to spot - try and crawl using the default 'response HTML' option and you won't get very far - you literally need to use a Chrome-based crawler (read How to Crawl JavaScript Websites for details why).
Sites that fall under #3 are the ones you need to worry about. With these sites, you could complete a crawl using your favourite crawling tool, in the default 'response HTML' mode, and it would look like you had collected all the data. It might crawl hundreds or thousands of URLs, and collect plenty of juicy technical SEO data. But some of it would be wrong.
It would be wrong because the website loads most of the data in HTML, but then on some pages, JavaScript fires and changes some of the content.
Here are some of the things it could change:
- Meta robots
- Canonicals
- Titles
- Meta Descriptions
- Internal Links
- External Links
As an SEO, if that doesn't worry you, you have your priorities wrong.
Let's rewind 1600 words (and 5-7 minutes you'll never get back), regarding the fundamental element of technical SEO that you need to understand;
- If the pages that should be indexed are actually indexed
- If the pages that should not be indexed are actually not indexed
To get the complete understanding of this that you need, for a given website, you need to know if JavaScript is getting involved during the render process and changing important data.
How to compare response vs render
Of course, one solution is to only ever crawl your websites with rendering switched on (i.e. using the Chrome Crawler in Sitebulb). Depending on your crawler of choice, and the website itself, this will be slower, consume more resources, and potentially cost you more money.
A more practical solution is to include 'Rendering' as one of your audit checks, and make it a matter of course to investigate if JavaScript changes content that you care about. You can do this by running audits both with and without rendering enabled, and comparing the results. Essentially the point of this is to determine the level of dependence upon JavaScript, and whether you need to render the pages in your audits moving forwards.
For the most comprehensive understanding of how JavaScript is affecting things, conduct a response vs render comparison report like this one in Sitebulb:
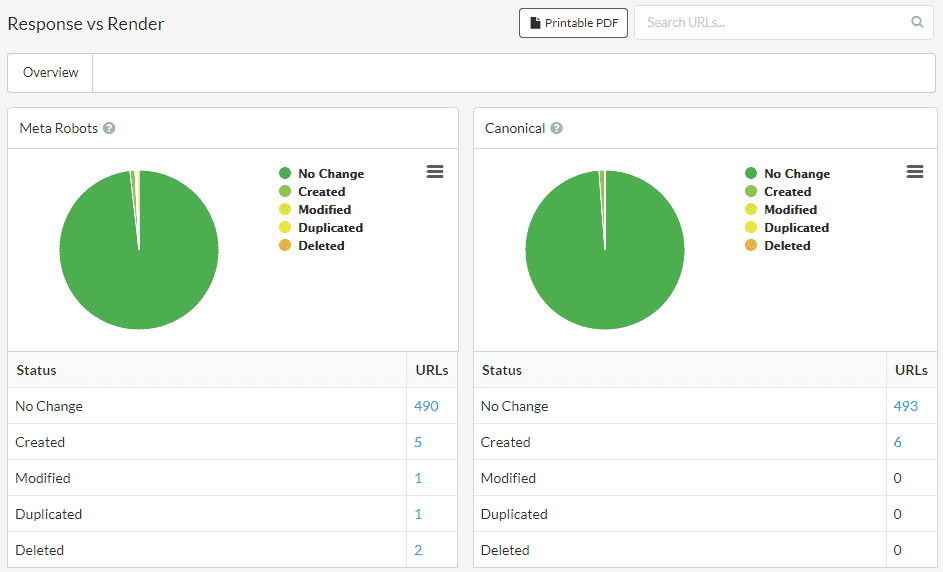
This allows you to easily see if JavaScript is creating new elements, modifying elements that are already there, duplicating elements, or going ahead and actually removing elements completely.
This might be due to JavaScript that was innocently added by a dev to solve a particular problem, but the side effects could have devastating effects - imagine a page that you intended to be indexed (and appears indexable when you check 'View Source') being 'secretly' changed by JavaScript to noindex?!
Why you need to investigate this stuff
As an advocate of technical SEO, I find these sort of statements from prominent Google representatives both alarming and frustrating:

As far as I can see, to "assume my pages get rendered and get on with it" is to fundamentally misunderstand the purpose of an SEO.
It's our job to not "just assume and get on with it". It's our job to not accept things on blind faith, but to dig and explore and investigate; to test and experiment and verify for ourselves.
"We will not go quietly into the night!"
President Thomas J. Whitmore, Independence Day
This is where we add the most value, dealing between the blurred lines of 'fact' and the realities of data, to understand specific situations for specific websites.
Google's job is to get it right in the aggregate, they don't really care about specific websites.
But SEOs do.
If you're dealing with a specific website where the rendered HTML contains major differences to the response HTML, this might cause SEO problems. It also might mean that you are presenting web pages to Google in a way that differs from your expectation.
You need to investigate it.
This sort of investigation will give you clarity between the blurred boundaries of Google's crawling process, when the response HTML is superseded by the rendered HTML. It will help you answer some otherwise opaque questions, like:
- Are pages suddenly no longer indexable?
- Is page content changing?
- Are links being created and modified?
Ultimately, these questions might not be important for Google... but they are important for SEOs.
If these things are changing during rendering, why are they changing?
And perhaps more pertinent still: should they be changing?
You might also like:




Patrick spends most of his time trying to keep the documentation up to speed with Gareth's non-stop development. When he's not doing that, he can usually be found abusing Sitebulb customers in his beloved release notes.



